Here is a How to Topic Maps, Sir!
It is said that people who write technical articles for the purpose of explaining a given something shouldn't know all there is to know about the given subject, as an exercise for the writer to become as knowledgeable about the given subject as the headline touts and hence feel the real pain felt by their readers in comprehending the same.
It is also said that the landing on the moon really happened in a film studio in London. Some say that Elvis isn't dead. A lot of things - as it happens - has been said about a number of things, but apparently nobody has said much about their CD collection and Topic Maps, and hence I rise forth to the tedious task of not knowing what I'm talking about to make you and me as knowledgeable about this subject as the headline reads.
This is not a tutorial. This is an essay written to be preceding a tutorial I'm writing about Topic Maps and how to Sort your CD collection with it, which in itself will come in parts. The reason for this prelude is two-edged; philosophy vs. real-life;
There is a great deal of philosophy involved in working with Topic Maps. Not in the sense of arguing for extentionalism or purport a theory of when cats die in boxes, but in the sense of epistemology, the philosophy of learning. It is about how we perceive things, how human cognition works, about how we label things, how we categorise and find our way in the vast information layer between our brains and our tools.
The other reason is that this essay was easier to write. Bare with me.
Why Topic Maps?
What are Topic Maps? No, let's start at the other end; what is a computer, and why did we design one? What need do we have for a computer? Well, the name says a lot of it; we need to do computations, and a computer these days is all about processing vast amounts of information as fast as possible. But the computer is a very logical thing, and humans are not, despite rumours that says otherwise. For a computer to work, humans must tell it what to do, and for a logical beast to behave the way a human wants it to behave, they need to come to certain compromises; The computer must act as if it was a bit more human, and the human must act a bit more logically. These compromises are also known as abstractions, and a world-wide all-truth all-encompassing goal is to make abstractions that are as close to human nature as possible without losing that logical processing power.
We keep trying to create technological solutions that resemble human nature so that the information can be processed and handled as good as possible by both man and machine. Sometimes the abstraction happens in the user interface, where we create a cute icon for a complex computation or write the word "do" when what really happens is "do, fiddle, tweak, load, count, compute, save, tweak, squiggle, save again, spit and you're done." Other times the abstraction happens on a data model level, creating tables in such a way as to make human sense. Maybe the abstraction is on a hardware level. And, in fact, bits of abstractions are everywhere, from the inner CPU out through software to the keyboard you type on and the screen you're viewing. Unfortunately, all these bits of abstractions don't necessary make it easy to grasp what is going on, because they are - surprise, surprise! - bits that more often than not speak their own parables, and don't form a complete story.
Topic Maps is an abstraction that tries to bring together quite a lot of these bits, from the data model to the user interface, making an effort to try to tell the same story across the many layers we have in computers. And as such, it not only permutes through the technical layers of "data model" and "user interface", but also the people involved in using it, from designers and developers, project managers and general management, to users and interested parties. John the developer can now speak in the same language as the user, which is no small feat in itself and one that should lower the cost of miscommunication.
Topic Maps tries hard to lower the cost of miscommunication. It is a data model and accompanying exchange formats and API's that share a common set of terms, so when the user speaks about a bad association role, we all know - from the content producer that put it there, to the developer that implements the functions to do it, to the manager that handles the users request - exactly what that is.
For many, this is music to their ears.
Music
What is music? A simple question we all know the instinctive answer to, but often fail to formalize. One much used statement is that music is "the art of arranging sounds in time so as to produce a continuous, unified, and evocative composition, as through melody, harmony, rhythm, and timbre." [ Dictionary.com] Now, as much fun as we could have going through the academics of music, let's just note for the record that music ain't as straight forward to classify as many would like it to be.
Dictionary.com] Now, as much fun as we could have going through the academics of music, let's just note for the record that music ain't as straight forward to classify as many would like it to be.
We could go to Amazon.com and have a look at what's on offer:

Something for everyone it seems, and poking into each of these categories we find yet more sub-categories, related categories and subjects, searches and recommendation. In fact, Amazon.com does a pretty darn good job in assisting us in trying to find what we're after. In my case, I'm after a new recording of Monteverdi's Marian Vespers published in 1610. Under "classic" I could use the "historical period" link to brush forth to the baroque era - although it could be renaissance, and neither this or baroque are classical, but never mind the nitpicking - or search for "Vespro della Beata Virgine" or "Monteverdi" or both, or I could browse composers under "M". I'm pretty confident that what's available will come up; my trust in superior technology is paramount.
I search for "Claudio Monteverdi", and the "most popular search for Monteverdi" is his eight book of Madrigals, and hence not what we're after. In the full list of our search for Monteverdi, the first CD that pops up has nothing of Monteverdi to do with it. Nothing at all. Neither does the second. Nor the third. What's up with that? Umm, this is definitely the wrong tree. Let's try something else as I must have done something wrong.
I click on "related searches" to get to just "Monteverdi"; that surely must be the right way to go. Now, this gave me three CD's of two of Monteverdi's operas, and the old list above of unrelated CD's. But I'm not after opera, I'm after vespers. My bad.
Ok, I'll try a search for "Monteverdi vesper"; that ought to do the trick. It found three; first one has excerpts, the second too, and the third is an out of stock version of the vespers. Now, I personally have several recordings of these vespers, and none of them showed up in the search. Alright, alright, I'll try historical time period. Then go to baroque. And then either vocal music or religious and sacred music. Hmm. Let's try sacred. Now a massive list pops up, and I do a search for "Monteverdi" within this context, umm, which brings up one CD without any Monteverdi music on it.
Ok, last try, and straight for the jugular; I do a general search for "Parrott Vespers Monteverdi". That surely must yield what I want. And lo and behold; the first CD is the 2000 reissue of the 1996 recording of the vespers by Andrew Parrott. Ok, fine and well, I found something familiar, but I was after something else; who and what are the latest release of these vespers? What is related to this familiar one that I finally found?
Well, Boston Baroque has a version of it from 1997, and got good reviews I see, but I know there are many, many more of it. For someone like me, who study music and embark on journeys of pilgrimage just to hear a 17th version of a "Psalmus 109: Dixit Dominus", diversity is very, very important. And, as such, a problem with most CD collection software I've had the displeasure of using over the years, just like my problem with Amazon.com.
Classification
The story so far tells us a tale of certain types of music that can be classified in many ways, and that of the misguided attempts by yours truly to trust that a computer system gives what is expected of them, which also points to the problem of findability. My musical thirst seems to be hindered by the fact that my music can be performed in various ways, giving further classifications to it not automatically present in general terms, it can be re-issued, re-recorded, re-ordered, re-performed, re-opened, re-searched and / or re-decorated. There are so many 'fuzzy' things about music that it has proven to be one of the more challenging problems to solve.
But why this fuzz about music and Amazon.com? You'll see later that Topic Maps lends itself to a natural way of doing classifications, point to resources and merge information from different layers so that I wouldn't have to search and search and search in all the wrong places to get all the wrong results. To understand how Topic Maps can make things better, let's take a closer look at what my musical problem really is.
For me, Amazon.com did not do a good job, it did not meet my expectations, and did not provide what I wanted. In fact, the same search job in Google.com gave by far better results, even to items within Amazon.com itself, but that is another story. However, the jolt gave us some important hints to why music is so difficult.
The Marian Vespers of 1610 by Monteverdi are many things; sacred music, renaissance style, baroque style, Roman style, Venetian style, composed over several years, no evidence of being performed before its publication in 1610, uses several librettists, catholic music, show piece, adapted secular music, performed by many in many styles, recorded by many in many styles, played differently by many, played with different settings by many, basso continuo, a Capella, sad, joyous, separation of styles period, recordings re-issued many times, and so forth. You simply can't put it into one category, and feel happy about that.
Classifications touch on an area which is a bit risky; human cognition. It is the ultimate goal that a computer can use human cognition in terms of helping us process our data in best possible ways, because it lowers the cost - be it money, time, resources, power - of the interface between man and machine. Classification is a basic human function we perform all the time in order to gain some knowledge about things around us, but a computer, being a bit thick on the 'human' side but truly remarkable on the 'function' side, needs to convert data between human thinking and computational power. Remember what was said earlier about finding the best abstraction between computer logic and human concepts.
As such, we delve into more philosophical ponderings in search of good abstractions, and come up with something well known within the library world, called faceted classification, that a 'thing' can fit into more than one universal category. Faceted classification usually solves the problem of finding subjects with a great many options like this, be it top-down classification or more complex clustered facets. A common view about information like this is that there is an inner truth, some point you can cling to, and add as many property values as you need to it. So, "Marian Vespers of 1610" - a nice point to cling related information to - can have all of our facets listed above as properties; is-a sacred music, is-in this style, has-a setting, been-recorded by, and so forth.
This is, in simple terms, the world view of the table; something has a row of columns with data about the thing in it. We create programs that converts that table of things and present them as human as possible, and for record-keeping with a finite set of properties, this works like a charm. But what happens when we got infinite sets of properties attached to a thing? We create more tables to hold more versatile properties, and make 'relational links' between those tables. Welcome to the very common world of relational databases.
From tables to nodes
In the relational database, that magic "point to cling related information to" is a row in a table. It is one thing, a subject, a point, a node, whatever, and we put properties on it. We can have a table called "works", and chuck in a lot of rows representing each work Monteverdi has ever written. At row 6, we find "Marian Vespers", and in our table there are columns like "published", "composed", and "librettist".

Oh sure, this is a simple mock-up of a table, but it will demonstrate some very important things;
If something has more than one name, such as a nickname or a name in another language, what do you do? Add more columns and call these "nickname" and "latin_name"? As any sensible E-R designer knows, this is the time to refactor the model. We create a new table, call it "names" where we can put in as many names we like. Then we create a third lookup table to bind the information from "works" to "names". We could call this one "names_lookup", and voila! We then create some SQL to represent this, and create user-interface that a) knows about this data model and b) present it in the most likable fashion.
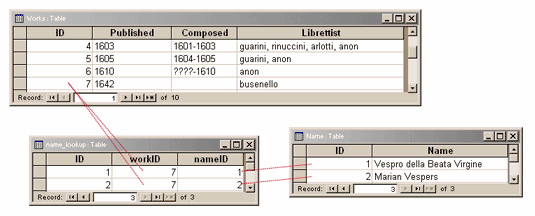
Yes, our names can now flow. Umm, apart from such questions as which name to use as a default name, which one to sort on, which one to use if your mothers sister just gave birth to triplets, or what name to use if the Moon is aligned with Venus. It is not safe to say, but by extending the "Name" table with further properties you could solve this problem. Unless there are many types of names, in which case it is easily solvable by creating a new table called "name_types" and another table called "name_types_lookup", create more brilliant SQL to represent this, and chuck a user interface on top of this that a) knows about this data model and b) present it in the most likable fashion. Yes, we can extend and fiddle with our data model like this until all the little bits of our information is properly dynamic.
So when that model is sufficiently huge, what have you got, apart from a legacy monster of a database that requires a massive team of specialists - in the model designed, in the SQL created, in user interfaces hence devised, in RDBMS for support, and in magic to make it all sound like a good thing to do? You've got an ugly, slow hog. And we don't want hogs; we want smooth and elegant and fast. Oh sure, you can design pretty smooth and elegant data models with plain vanilla RDBMS too, but the more complex the data, the more complex the data model, and the more hog it becomes. Legacy is something we're all trying to get away from, not embrace.
Some in the RDBMS world refer to maintaining these massive systems as putting lipstick on a hog, and apart from the technical challenges these systems can have (performance, cost, scalability, development) they are fragile because they require so much legacy knowledge about them, which in fact, many of these systems were designed to remove. A catch 22 indeed where we design complex systems to make it easier for the user in finding information, but in doing so we create hogs that are very difficult to maintain and develop.
Topic Maps is hence data model that can be recreated in a lot of existing tools, and there is a very good article by Marc de Graauw that demonstrates how you can use your RDBMS to create a Topic Maps model in it and use it for all the goodness that it gives, similar to what I demonstrate above.
But let's take a few steps back, and get back to that magic "point to cling related information to."
Putting the map back in Topic Maps
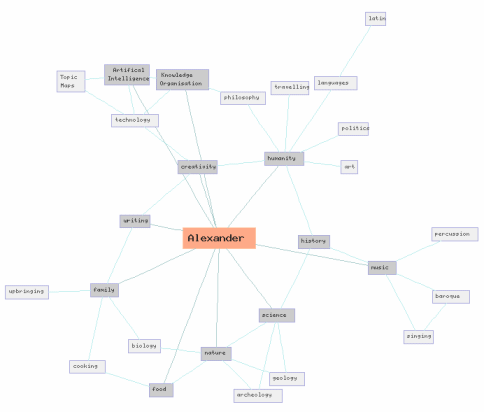
Let's talk about the "map" in Topic Maps first. Above is a map I did of myself some time ago. There is a magical "point to cling related information to" in the middle named after myself, in which I drew lines between that and other subjects I'm interested in. In the mathematic world this resembles what is know as a Graph, and mathematicians work on these with Graph Theory. I personally think it is just a pretty map of things I'm interested in. My subjects can just as well be cities, and the lines between them roads. It's just a map.
There is a strong correlation between a map and a category system where entering a category can be seen as zooming in on the map on a subject. There are two very interesting things about a map such as mine above; the subjects scattered about and the actual lines between them. In my map, the boxes represent "subjects" and the lines represent "interest". In graph theory my subjects are called "nodes" and the lines "edges". In Topic Maps, these are called "topics" and "associations." See, there is a red thread running through these maps.
Nodes. They are very small, and they don't really hold much value in and of themselves, but if we attach other nodes to it through associations / relations / roads they hold valuable information. This fact lies at the core of a Topic Map. There are topics, and the topics have associations. That really is all there is to it. No magic, no mystery, just plain vanilla logic that happens to resemble human nature in its simplistic form.
Now these nodes and associations on their own is all fine and well, but it isn't until we put them in some order or system that they can be used for something. After all, our much sought-after abstraction that is human and machine at the same time does not come from wild ideas about "nodes" and "edges" or "cities" and "roads", it comes from writing software on top of hardware to do the job. So, let's have a look at how we can do the job.
The truth about relational databases
The truth about relational databases is that they really are Topic Maps that are trying to get out. Think about what your RDBMS is trying to do; you have a lot of tables with information bits, and you create relations between them to represent something vital to your business requirements, write SQL to mirror that and try your best at fixing a user interface on top to make it all work. The more relations you've got, the more complex your model is going to be. And for what? To create an application that that both a computer and human can handle well.
Where do you stop expanding your model and when? When it gets too complex? Too slow? Too unmaintainable? Too crazy to keep going? Too often you get bogged down in the design of models; what relations are hogs, which ones are necessary, which ones are not? Why not look at it from the other direction; everything is in relation to something. Instead of learning all there is to learn about how to limit a model, why not learn all there is to learn about how to expand your application?
The truth about Topic Maps is that it is a data model that is very successful for a wide variety of applications, and I'm not talking about applications here as in "a program" but as in "an area in which to apply a solution."
Let's have a peak at a Topic Maps version of the RDBMS problem of music earlier on.
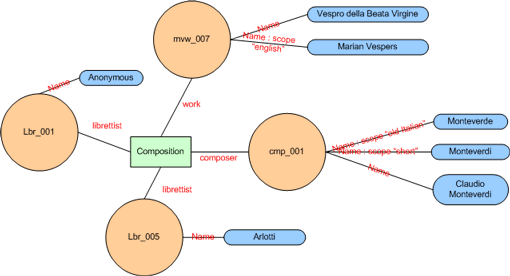
Now, before you panic, lets go through it slowly. There are four topics in this picture. Yes, that's right; the four circles are topics. They have funny labels which aren't labels at all, but ID's. In my passport there is a complicated number which tells the people reading it that the passport of Alexander Johannesen has this number. If it was a different number, it wouldn't be him. The same with a unique ID number in a database. It is a something that says that this thing is unique. The same for our topics; our ID must be unique so that we can point to this number and say "I'm talking about this one."
Each topic has one or more names associated with it. It isn't required to have a name, though, but it can be helpful to the human that was to fiddle with the map. Some of these topics also have more than one name, which is fine, and the names can have a "scope", meaning a determining value that says something about this name. Our example from "mvw_007" is the name "Vespro della Beata Virgine" for the unconstrained scoped name (meaning default for most things) and the name "Marian Vespers" with the scope "english." This means that the name "Marian Vespers" have a value ("English") which says something about it. We can use this for many things, but here it is used for languages of names. If someone viewed this Topic Map and told the Topic Maps application that she would only like to see topics with an English name, this scope on names is what the system use for determining what to display.
Finally, there are some green boxes that seems to hold relational information. Pay close attention to these; they are the backbone of the knowledge in a Topic Map. Note that each line coming or going from an association has a name, and these names are the roles of which the topics play in that association. The topic "mvw_007" obviously play the role of "work" in the association "Composition". To find the composer, you obviously look to the role of "composer."
If this still seems totally incomprehensible, this is a good time to panic. Get it over with and out of the system, because these things - albeit an abstract - is still just bits of data. They all - be it topics, associations or roles - represent … something. See, I told you there was some philosophy in there. Let's go to BASIC.
10 LET $topic_001 = "Monteverdi"
20 LET $topic_002 = "Marian Vespers"
30 LET $association_001 = $topic_001 + " : " + $topic_002
Here we have a very - very! - basic Topic Maps representation written in BASIC. It doesn't do much as such, but just like a variable in BASIC - a name that represent something - there are symbols that resolve to values. A 1-to-1 scenario could be our association at line 30. A number of functions can hence be written to perform various tasks based on these topics and associations. For more complex Topic Maps representation, however, we might turn to other computer languages more suited to the task, especially those that support object-oriented programming. Like PHP.
Class Topic {
Var $name = '' ;
Function Topic ( $name ) { $this.name = $name ; }
}
Class TwoWayAssociation {
$members = Array() ;
Function TwoWayAssociation ( $a1, $a2 ) {
$members[] = $a1 ;
$members[] = $a2 ;
}
}
$composer_001 = new Topic ( "Monteverdi" ) ;
$work_006 = new Topic ( "Marian Vespers" ) ;
$an_association = new TwoWayAssociation ( &$composer_001, &$work_006 ) ;
These are simple examples indeed, to prove a very simple point; Topic Maps are not as complicated nor difficult as many believe. There are objects that points to objects that points to objects. Objects are of certain types, and given a certain number of types behaving in a certain way, we call that a Topic Map. In a Topic Map we have three basic objects called Topics, Occurrences and Associations. Further we extend these with Names, Scopes, Roles and other specialised assetions; there we have an object model. Then we apply a number of rules to that object model (both in the sense of what objects to have what properties and links), and we have a Topic Map. Then a set of further rules to cooperate two or more Topic Maps together, and we have the Topic Maps we know of and practice today.
To lull you back into the safety of RDBMS for a small fraction of a second, think of the topics in our drawing above as rows in a table called "topics", and the green associations in another table called "associations". Relax with another table called "topics_associations_lookup". It's all data. Just data. But hang on; we don't want things in a table, we want our nodes of information to be a lot freer than that. We want to be able to attach any association to it without worrying about the flexibility of the "data model." We want to search our graph of nodes in clever ways, not top-down, because when you look at it, information isn't top-down; it is associative. The abstraction level of the RDBMS works well for records, but not all that well for information that should - in some mysterious way - resemble human cognition.
So take note; the rules we apply through table definitions and the functional SQL shapes the same thing; data objects and rules together to be called Topic Maps, as long as these definitions and SQL statements comply with the Topic Maps standard. And that's all there is to it.
Think of the topics and associations as stand-alone objects that have small bits of data attached to them. For those who are in the deep end of object-oriented programming may think "Hey, wait a minute! This is nothing but a tree structure with various properties attached to the nodes." And you would be absolutely correct in that. That is what it is, with certain names and labels attached in clever ways. No magic. No smoke and mirrors. Just a nice little data model with some rather clever ideas and rules through it. Welcome to Topic Maps.
The end
Well, well, we're at the end of the essay, and I hope I've given you some taste of what Topic Maps are and how they can be applied, and a small grasp of the concepts involved. I realise that I haven't solved any actual problem thorugh this essay, such as showing you how to actually build a CD collection software with Topic Maps to demonstrate its incredible oomph. Fear not; the tutorial in writing will be attacking this exact problem. Until then, Monteverdi's "Leatatus Sum" signs off its rolling hills, and lulls me back into Venetian comfort.
Labels: data modelling, semantic web, topic maps