Ressurection : xSiteable Framework
I've just started in my new job (yes, more on that later, I know, I know) and was flipping through a lot of my old projects over the years, big and small, and I was looking for some old Information Architecture / prototyping tool / website generator application I made with some help from IA superstar Donna Spencer (nee Maurer) back when I lived in Canberra, Australia.
I found three generations of the xSiteable project. Generation 1 is the one a lot of people have found online and used, the XSLT framework for generating Topic Maps based websites. I meant to continue with generation 2, the xSiteable Publishing Framework (which runs the Topic Maps-based National Treasures website for the National Library of Australia) but never got around to polishing it enough for publication, and before I came to my senses I was way into developing generation 3, which I now call the xSiteable Framework (which sports a full REST stack, Topic Maps. And yes, I'm still too lazy to polish it enough for publication (which includes writing tons of documentation), at least as of now, but I showed this latest incarnation to a friend lately, and he said I had to write something about it. Well, specifically how my object model is set up, because it's quite different from the normal way to deal with OO paradigms.
First of all, PHP is dynamic, and has some cool "magic" functions in the OO model which one can use for funky stuff. Instead of just extending the normal stuff with some extras I've gone and embraced it completely, and changed my programming paradigms and conventions at the same time. Let's just jump in with some example code;
You might also have noticed ... users->ajohanne->email .... Where did that "ajohanne" bit come from? Well, as things are designed, again the framework will try to find stuff that isn't already found, so "ajohanne" it will automatically look up in designated fields. All objects that extend the framework have two very important fields, one being the integer primary identifier, the second one the qualified unique name (so not a normal name as such, but a most often a computer generated one that isn't normally a number. Often systems will use things like a username, say, as a qualified name, and hence "ajohanne" was my username in one such system). Why do this?
Well, PHP is dynamic, so in my static example above, explicitly using 'ajohanne' as part of the query, isn't the best way to go in more flexible systems, but just pop your found user in dynamically instead;
Traditionally, we use getters and setters ;
A long time ago I thought that the link between persistent URI's for identity management in Topic Maps and the URI (and using links as application state) in REST were made for eachother, and I wanted to try it out. In fact, that fact alone was the very inspiration for me to do the 3rd generation of xSiteable, hacking out code that basically has one URI for every part of the Topic Map, for every part of the TM API, and for other parts of your application. Here's some sample URIs ;
All in all, this means I have many ways into the system and its data, none of them more correct than the other as they all resolve to topics in the topic map. This lowers the need for error checking greatly, and the application is more like a huge proxy for a Topic Map with a REST interface. It's a cute and very effective way of doing it. I'm trying various scaling tests, and with the latest Topic Maps distribution protocols that I can use for distributing the map across any cluster, it's looking really sexy (although I still have some work to do in this area, but the basics rock!).
Anyway, there's a quick intro. I guess I should follow this up with some more coded details of examples. Yeah, maybe next week, as I need to get some other stuff done now, but I like the object model I've got in place, and it's so easy to work with without losing the need for complex stuff. Take care.
I found three generations of the xSiteable project. Generation 1 is the one a lot of people have found online and used, the XSLT framework for generating Topic Maps based websites. I meant to continue with generation 2, the xSiteable Publishing Framework (which runs the Topic Maps-based National Treasures website for the National Library of Australia) but never got around to polishing it enough for publication, and before I came to my senses I was way into developing generation 3, which I now call the xSiteable Framework (which sports a full REST stack, Topic Maps. And yes, I'm still too lazy to polish it enough for publication (which includes writing tons of documentation), at least as of now, but I showed this latest incarnation to a friend lately, and he said I had to write something about it. Well, specifically how my object model is set up, because it's quite different from the normal way to deal with OO paradigms.
First of all, PHP is dynamic, and has some cool "magic" functions in the OO model which one can use for funky stuff. Instead of just extending the normal stuff with some extras I've gone and embraced it completely, and changed my programming paradigms and conventions at the same time. Let's just jump in with some example code;
// Check (and fetch) all users with a given emailTables are are contextually defined in databases, so $this->database->users points directly to the 'users' table in the database. (Well, they're not really table names, but for this example it works that way) The framework checks all levels of granularity, and will always return FALSE or the part-object of which you want, so for example ;
$usercheck = $this->database->users->_find ( 'email', '' ) ;
// Get the domain of a users email addressAgain, it's like a tree-structure of data, a stream of granularity to get in and out of the data. This does require you to know the schema (and change the code if you change the schema), but apart from that, in a stable environment, this really is helpfull (it's also cached, so it's really fast, too).
$domain = $this->database->users->ajohanne->email->__after ( '@' ) ;
You might also have noticed ... users->ajohanne->email .... Where did that "ajohanne" bit come from? Well, as things are designed, again the framework will try to find stuff that isn't already found, so "ajohanne" it will automatically look up in designated fields. All objects that extend the framework have two very important fields, one being the integer primary identifier, the second one the qualified unique name (so not a normal name as such, but a most often a computer generated one that isn't normally a number. Often systems will use things like a username, say, as a qualified name, and hence "ajohanne" was my username in one such system). Why do this?
Well, PHP is dynamic, so in my static example above, explicitly using 'ajohanne' as part of the query, isn't the best way to go in more flexible systems, but just pop your found user in dynamically instead;
$domain = $this->database->users->$username->email->__after ( '@' ) ;Easy. And this applies to all parts of the tree, so this works as well ;
$domain = $this->database->$some_table->$some_id->$some_field->__after ( '@' ) ;No, from the two examples above we might see a different pattern, too. All data parts has unrestrained names, all query operations use an underscore, and all string operations uses two underlines. (__after is a shortcut for substr ($str, strpos ( $str, $pattern ) ), and I've got a heap of little helpers like this built in ) Through this I always know what the type of the object interface is, and with PHP magic functions these types are easy to pull down and react to. As some of my objects are extendable, I need to pass _* and __* functionality up and down the object tree.
Traditionally, we use getters and setters ;
$u = $obj->getUsername() ;I turn them all into properties, so ;
$obj->setUsername ( $u ) ;
$u = $obj->username ;But they are still full internal functions to the object, and this is another magic function in PHP ;
$obj->username = $u ;
class obj extends xs_SimpleObject {The framework isn't just about object persistence. In fact, it is not about that. I hate ORMs in the sense that they still drag your OO applications back into the relational database stoneage with some sugar on top. In fact what I've done is to implement a TMRM model in a relational database layer, so it's a generic meta model (Topic Maps) driving that backend and not tables, table names, lookup tables, and all that mess. In fact, crazy as it sounds, there's only four tables in the whole darn thing. I'm relying on backend RDBM systems to be good at what they should be good at; clever indeces, and easier joins in a recursive environment (which, when all data is in the one table, it indeed is recursive), where systems use filters to derive joins instead of doing complex cross-operations (which takes lots of time and resources to pull off, and is the main bottleneck in pretty much any application ever created which has a database backend.
function getUsername () {
...
}
function setUsername ( $value ) {
...
}
}
A long time ago I thought that the link between persistent URI's for identity management in Topic Maps and the URI (and using links as application state) in REST were made for eachother, and I wanted to try it out. In fact, that fact alone was the very inspiration for me to do the 3rd generation of xSiteable, hacking out code that basically has one URI for every part of the Topic Map, for every part of the TM API, and for other parts of your application. Here's some sample URIs ;
http://mysite.com/prospect/12At each of these there are GET, PUT, POST and DELETE options, so when I create a new prospect, it's a POST to http://mysite.com/prospect or a direct PUT to http://mysite.com/prospect/[new_id], for example.
http://mysite.com/api/tm/topics/of_type:booking
http://mysite.com/admin/db/prospects
All in all, this means I have many ways into the system and its data, none of them more correct than the other as they all resolve to topics in the topic map. This lowers the need for error checking greatly, and the application is more like a huge proxy for a Topic Map with a REST interface. It's a cute and very effective way of doing it. I'm trying various scaling tests, and with the latest Topic Maps distribution protocols that I can use for distributing the map across any cluster, it's looking really sexy (although I still have some work to do in this area, but the basics rock!).
Anyway, there's a quick intro. I guess I should follow this up with some more coded details of examples. Yeah, maybe next week, as I need to get some other stuff done now, but I like the object model I've got in place, and it's so easy to work with without losing the need for complex stuff. Take care.
Labels: knowledge representation, php, rest, SOA ROA WOA REST SOAP WS architecture, topic maps



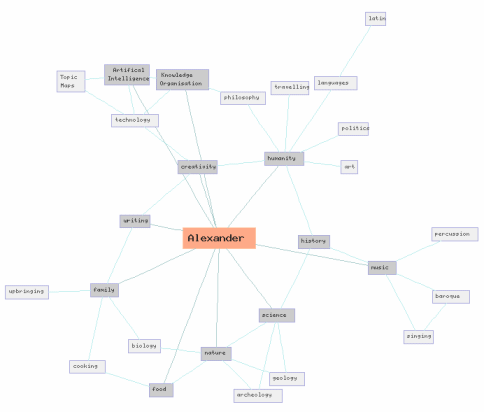
 Here's a model of me. (If you can see it properly, ) Does it seem right to you?
Here's a model of me. (If you can see it properly, ) Does it seem right to you?